
Concurrency vs Parallelism — Stop Mixing Them Up
Part 1 of "Building Software That Doesn't Fall Over"

Intro
Welcome back to Tech Unpack. This is the first deep dive in a seven-part series called “Building Software That Doesn’t Fall Over” — a tour through the engineering decisions that separate systems surviving real production load from systems that buckle the moment traffic spikes.
A production-grade service has to solve a whole stack of problems: handling huge volumes of concurrent requests, sharing state safely between them, absorbing traffic spikes without crashing, scaling out across machines, surviving database bottlenecks, caching without going stale, and staying observable when things break. Each of these gets its own post in this series.
Today we’re starting with the foundation everything else sits on: how do you serve thousands of concurrent requests on a single machine without it grinding to a halt?
The answer comes down to picking the right tool for the workload — and that means getting clear on three concepts that get tossed around interchangeably but actually mean very different things
The three words, explained simply
Picture a typical workday at the office.
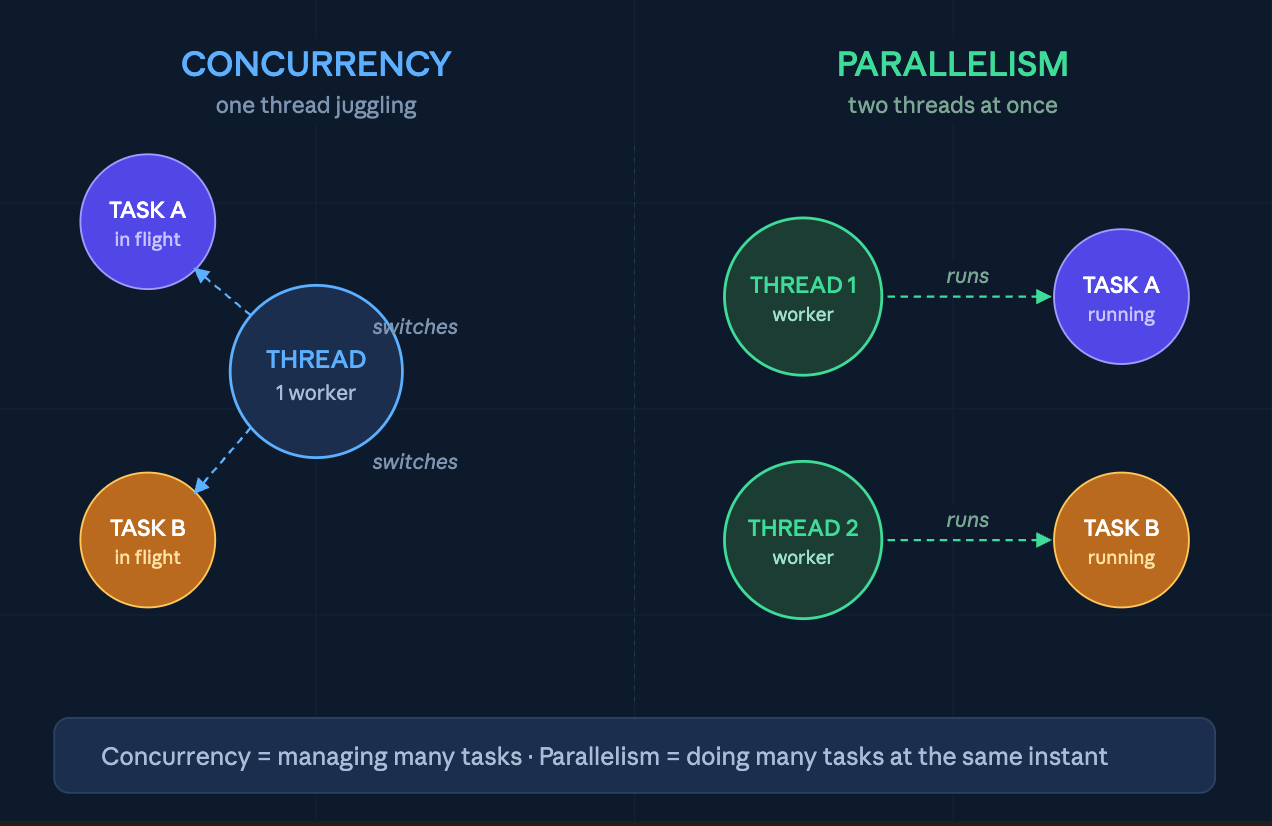
Concurrency is managing multiple tasks at once. You’re on a Zoom call, but while someone else is talking, you reply to a Slack message. You’re not doing two things at the exact same instant — you’re juggling them. One person, multiple things in flight.
Parallelism is actually doing multiple tasks at the same instant. You and a colleague each handle your own meeting, at the same time. Two people, two meetings, real wall-clock speedup.
Async is a way to handle concurrent work without blocking. Instead of sitting there refreshing your inbox waiting for a reply, you send the email and move on. When the reply lands, your laptop pings. It’s a way of working, not a separate concept.
The trap most devs fall into: async code is concurrent, but not parallel. A single Node.js event loop juggles thousands of async tasks — but only one runs at a time. If that one task hogs the CPU, everything else waits.
Concepts in action
The best way to understand and apply these concepts are by looking at it in a demo. But before going to the fun parts, there are 2 more concepts we need to clear our head. (Yes explain something by giving definitions to something else 😭)
I/O-bound work is anything where your code is waiting on something external — a network response, a database query, a file read, an API call. The CPU sits idle during the wait. If you timed the work, most of the milliseconds would be “doing nothing, waiting for someone else.”
CPU-bound work is anything where your code is actively computing — hashing, parsing, image resizing, regex matching, JSON-serializing a huge object. The CPU is pegged the whole time. There’s no waiting; there’s just work.
A simple test: if a faster network would speed up the task, it’s I/O-bound. If a faster CPU would speed it up, it’s CPU-bound.
Demo: same task, three approaches
I built a small TypeScript demo that runs two tasks — one I/O-bound, one CPU-bound — three different ways: sequential, async-concurrent (Promise.all), and parallel (worker threads). The full code is on GitHub if you want to clone and run it yourself:
👉 github.com/jackdo68/concurrency-demo
So basically there are 2 files in the code base (you already can guess, one for I/O tasks, one for CPU intensive tasks) called io-demo.ts and cpu-demo.ts.
I/O demo I ran an actual HTTP request to an server using 2 manner sequential and concurrent. And the result as you can tell, the “concurrent” will finish first, because while wait for the response of one, the machine can start doing the job of another. The screenshot below shows the result logs in milliseconds
> concurrency-demo@1.0.0 io
> tsx io-demo.ts
Sequential: 15162ms
Concurrent: 3172msCPU demo is about running multiple CPU tensive tasks in 3 manners sequential, promise.all/async and parallel (spawn up child workers). Since the CPU has to actually do the work here, sequential and async manner roughly has the same latency (in fact async has some overhead and actually takes longer) while parallel really shine (but of course with extra help of sub workers/child process)
> concurrency-demo@1.0.0 cpu
> tsx cpu-demo.ts
Sequential: 4300ms
Promise.all: 4325ms
Parallel: 2236msI know the concepts, what now?
Here’s where the three concepts become a toolkit. Most production outages I’ve seen come from one of three mistakes — and each one maps to a misuse of these concepts.
Mistake 1: Treating I/O work like CPU work
Example A service makes 50 calls to downstream APIs, one after another. Each takes 200ms. Total: 10 seconds. Under load, requests pile up, the server hits its connection limit, and everything starts 504-ing.
The fix: async concurrency. Fire the calls together with Promise.all (or asyncio.gather, or a Go errgroup) and total time drops to ~200ms. Same server, same hardware, 50x throughput on that endpoint — for free.
Resilience principle: Never wait sequentially for things that don’t depend on each other. This is the cheapest performance win in software, and the easiest one to miss. Companies like Netflix, Uber, and PayPal lean heavily on Node for I/O-heavy services — API gateways, real-time feeds, backends-for-frontends — where holding thousands of open connections cheaply matters more than raw compute. Node JS - Event loop
Mistake 2: Treating CPU work like I/O work
Example A team adds image resizing to their Node API. They wrap it in async/await and assume the event loop will handle it. Under load, every request waits for the resize to finish — because the event loop is one thread. P99 latency goes through the roof. Health checks start failing because the loop can’t even respond to /health for 800ms at a time. The load balancer marks the instance unhealthy, traffic shifts to the survivors, and they fall over too.
The fix: offload CPU work to a worker pool so the event loop stays free. Or better, push it to a separate service entirely (a queue plus dedicated workers).
Resilience principle: CPU work needs its own lane. If a single slow operation can block your health check, your load balancer will eventually kill the instance and your traffic will cascade onto whoever’s left. Instagram runs a Django monolith on Python, which has the Global Interpreter Lock (GIL) — only one thread executes Python bytecode at a time — so they sidestep it with a multiprocess model behind Gunicorn, running many worker processes per machine. Instagram - Engineering
Mistake 3: Unbounded concurrency
Example The opposite of mistake 1. A dev hears “use Promise.all“ and fires 10,000 DB queries at once. The connection pool is exhausted in milliseconds. The DB starts queuing, then timing out. Suddenly every service sharing that DB is degraded — including the ones that had nothing to do with this request.
The fix: bounded concurrency. Use a semaphore or a library like p-limit to cap how many things run at once. Twenty in flight at a time is usually plenty.
Resilience principle: Concurrency is a resource — budget it. “As fast as possible” usually means “fast enough to break something downstream.” We’ll go much deeper on this in Part 3 (backpressure).
Conclusion
Thanks for being patient and keep reading until this point, but this is just only the beginning. Once you have multiple things running at once — async or parallel — they start stepping on each other. Two requests update the same counter. A cache write races a cache read. Welcome to shared state, the bug factory at the heart of every concurrent system.
Next post: race conditions, mutexes, and why “just add a lock” is the start of a much longer conversation.