
Horizontal Scaling — Load Balancers, Sticky Sessions, and What "Stateless" Actually Requires
Part 4 of "Building Software That Doesn't Fall Over"

Intro
Welcome back to another article of “Building Software That Doesn’t Fall Over”. Parts 1 through 3 stayed close to the internals — how processes handle concurrency, how shared state breaks under contention, how pipelines protect themselves from being flooded. All of it happening inside individual components.
Now we step back and look at the application tier as a whole. Your API servers. The layer that receives every user request. What happens when one instance can't keep up — and you need to run ten of them in parallel?
That's a different class of problem. And it has one non-obvious requirement: your servers need to be stateless.
What "stateless" actually means
A stateless service holds zero knowledge about past requests in its own memory. Every request arrives with everything the server needs to handle it. The server doesn’t remember you from a millisecond ago.
That sounds obvious. It’s not. Most apps accumulate state without realising it: an in-memory session, a local file cache, a websocket connection pinned to one process. Each one is a hidden coupling between a user and a specific server instance.
This is fine when you run one server. The moment traffic grows and you need to scale horizontally — spin up more instances and split the load across them — those hidden couplings explode. Any state stored inside one instance becomes invisible to every other instance.
Horizontal scaling in actions
When you scale horizontally, you're not making one server faster. You're running multiple identical copies of your app in parallel and splitting incoming traffic across them. If we use AWS as an example, there are three common setups you can do ( I believe other cloud providers have equivalent services, but explaining them is out of scope for this article)
API Gateway → Lambda: For serverless APIs. Each Lambda invocation is its own isolated execution — it spins up, handles one request, and disappears. AWS manages scaling automatically; you never think about instances. Statelessness is enforced by design — Lambda has no persistent memory between invocations.
API Gateway → ALB (via VPC Link): When you want API Gateway at the public edge (for auth, throttling, caching) but your actual service runs in containers inside a private VPC. API Gateway tunnels requests through a VPC Link to an ALB, which then routes to your containers. You manage statelessness yourself.
ALB → EKS pods: The most common setup I see for distributed system that use K8s. ALB sits at the edge and distributes traffic across pods running inside a Kubernetes cluster. Pods scale horizontally via HPA. You manage statelessness yourself.
We’ll focus on setup 3 — it’s the most common for production backend services, and the one where statelessness requires the most deliberate work.
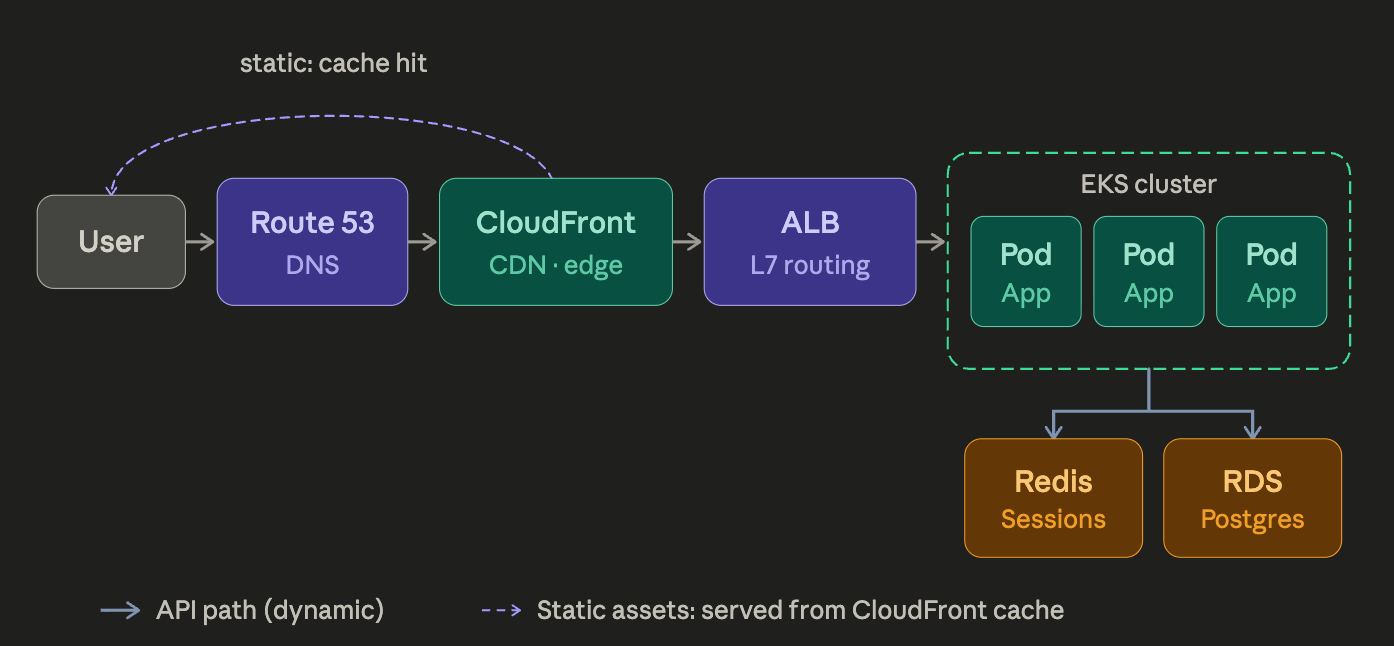
A simple diagram showing the flow from client app through to different AWS services to the cluster
ALB: what it is and what it does
ALB stands for Application Load Balancer. It’s an AWS-managed service that sits in front of your pods and routes each incoming request to one of them. It operates at HTTP/HTTPS level — meaning it can inspect the request and route based on path (/api/* goes to your API pods, /static/* goes to your static file service), host header, or HTTP method.
It doesn’t know anything about your app logic. It reads headers, matches a rule, picks a pod, forwards the request. That’s it.
One non-obvious side effect: your pods see the ALB’s internal IP as the request origin, not the client’s. ALB injects the real client IP into a header called X-Forwarded-For. If your app uses client IP for rate limiting or logging, read that header — not req.socket.remoteAddress.
// Your app reads the real client IP from the ALB-injected header
const clientIp = req.headers['x-forwarded-for']?.split(',')[0].trim();
// ↑ ALB may chain multiple IPs if the request
// passed through more than one proxy
// — the first one is always the original client
// NOT this — this gives you the ALB's internal IP, not the user's
const wrong = req.socket.remoteAddress;Scaling pods with HPA — and why statelessness is the prerequisite
With ALB in front, Kubernetes HPA (Horizontal Pod Autoscaler) can scale your pods automatically. It watches CPU across all running pods — when average utilisation crosses a threshold (say 60%), it spins up new replicas. ALB detects the new pods via health checks and starts routing traffic to them within ~30 seconds.
Here’s the catch: that new pod is empty. If your app stores anything inside the pod — a user session in memory, a local file, a WebSocket connection — the new pod has none of it. Users whose requests land there get logged out. Their cart is gone. HPA scaled you out, and things got more broken.
The same failure hits when a pod crashes. If you were using sticky sessions (routing each user to the same pod via a cookie or IP), the load balancer can reroute in milliseconds — but the new pod has never heard of those users.
The fix: anything that needs to survive across pods must live outside the pods.
// Before: session lives in process memory — pod restarts, session gone
app.use(session({
secret: process.env.SESSION_SECRET,
resave: false,
saveUninitialized: false,
// Default MemoryStore: tied to this process, not portable across pods
}));
// After: session lives in Redis — any pod can read it on any request
app.use(session({
store: new RedisStore({ client: redisClient }),
secret: process.env.SESSION_SECRET,
resave: false,
saveUninitialized: false,
cookie: {
maxAge: 1000 * 60 * 30, // 30 min TTL — Redis auto-expires stale sessions
httpOnly: true,
secure: true,
},
}));
// Sticky sessions no longer needed — any pod serves any userNow HPA can do its job. Pod crashes, pod scales up — it doesn’t matter. Every pod reads from the same Redis. State lives outside the app, so every pod is truly interchangeable.
One caveat: HPA watches CPU, not your database. If your DB is already struggling at 3 pods, adding 10 more just means 10x the connection pressure on the same bottleneck. We will look into this in the next part of the series.
Key takeaways
Before you declare a service stateless, check every one of these:
In-memory session store → move to Redis or a database
Local file writes (uploads, temp files) → move to S3
WebSocket connections pinned to one instance → use a pub/sub layer (Redis Pub/Sub, or a managed service like Pusher) so any instance can push to any client
In-process job queues (Bull without Redis backend, or setTimeout-based queues) → move to SQS or a Redis-backed queue
Service discovery hardcoded to a specific instance IP → use DNS or a service mesh
Conclusion
Congrats on reading up to this point. Hopefully you know roughly how to write the server code of a system that scale horizontally. But we don’t stop it here, next part we will look at the database layer and what we need to be cautious about scaling when the server is talking to the database. See you there!