
The Shared State Problem — How real world system actually solve it
Part 2 of "Building Software That Doesn't Fall Over"

Intro
Welcome back to my deep dive system design series, if you guys read part 1 and find them useful, this article will be the following step to answer some of the questions you may have. In previous part, we talked about concurrency, parallelism and async.
Here's the thing nobody tells you after you understand async: running things concurrently creates a new class of bug. Two requests touch the same balance. A counter drifts. A user gets charged twice. The fix sounds obvious — "just add a lock" — until you realize that's the beginning of the problem, not the end.
In this article I will go into the implementation of 2 famous technologies Postgres and Redis, so we can understand how each of them tackle the shared state problem. The third example will be from Stripe - a well known payment processor which we will see how ‘shared state issues’ got addressed at a distributed system.
The technical detour
Before deep dive into practical implementations, the following terms are quite common that I think we should get our head around.
Race condition — is what happens when the correctness of your program depends on the order in which concurrent operations run — and that order isn’t guaranteed. It’s not that the logic is wrong; it’s that the order has been messed up.
Mutex — (mutual exclusion lock) is a flag that says “only one thing at a time can be in this section of code.” Threads or async tasks line up, take turns, release. Some good examples here are threading.Lock() in Python, or sync.Mutex in Go.
Atomic operation — is a single instruction the CPU promises to complete without interruption. “Add 1 to this number” sounds like one step but is actually three (read, add, write). Atomics make it genuinely one step, so no other thread can sneak in between. Atomic is a fundamental part in ACID transactions property that make engineers choose RDBMS to prioritizes consistency over availability.
Optimistic concurrency — flips the whole model. Instead of locking before you read, you read freely, do your work, and at write time check “is the data still what I saw?” If yes, commit. If no, retry. No queueing, no waiting — but you pay for it in retries when contention is high.
How the smart systems actually handle it
Postgres — versioning instead of locking

When txn 101 updates acc_42, Postgres doesn't overwrite the row. It writes a new version of it — tagged with the transaction ID that created it (xmin=101). The old row stays on disk, tagged as visible to transactions that started before 101. That's why txn 100 — a long-running analytics query — still reads $1,000 while txn 101 is writing $300. They're reading different physical rows, both legitimate, neither blocking the other. The cost is storage: old row versions accumulate until vacuum reclaims them, which is why long-running transactions are dangerous — they pin old versions that vacuum can't touch. Deep dive on MVCC, vacuum, and the connection pool problem in Part 5.
Redis — sidestep the problem entirely
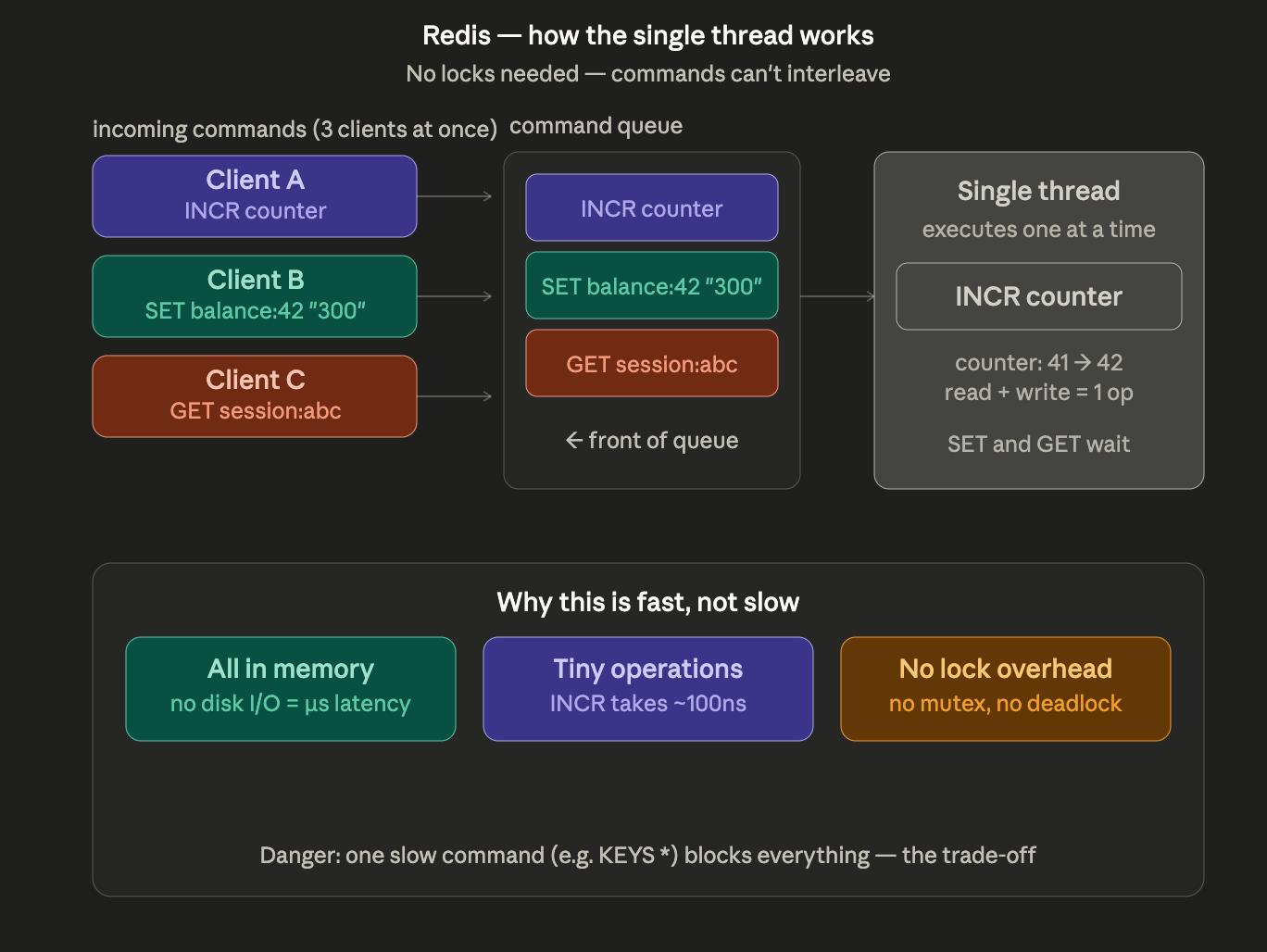
Redis doesn't solve concurrent shared state — it makes it structurally impossible. Every command from every client lands in a single queue. The event loop pops one command, runs it to completion, moves to the next. INCR counter is a read, increment, and write — but because nothing else can run between those steps, it's atomic by design, not by locking. The cost is that one slow command (KEYS *, a blocking LRANGE on a 10M-item list) stalls every other client. Redis is fast precisely because its operations are tiny. If you're running big operations, you're using it wrong. Cache stampedes and why "just put Redis in front of it" has its own failure modes: Part 6.
Stripe — idempotency keys for distributed shared state

Once state lives across machines, in-process locks and MVCC stop helping — a network retry doesn't care what's in your mutex. Stripe's answer is a lookup table. Before executing anything, the server checks: have I seen this key before? First time — insert a row, run the charge, store the result, mark complete. Duplicate — return the stored result, never touch the payment processor. The elegance is in the processing state: if the first request is still in-flight when the retry arrives, the server returns a 409 Conflict and the client backs off. The distributed coordination problem reduces to a single database row. Distributed locks, Redlock, and the CAP theorem trade-offs in a later post.
I know the concepts, what now?
The following are some common mistakes that I found even seasoned engineers can make.
Mistake 1: Wrapping everything in a giant lock
A team hits a race condition, panics, and wraps the entire request handler in a global mutex. Bug fixed. Throughput drops 90%. Lock the smallest unit you can — a row, a key, a single object. Better yet, ask whether the problem can move to the database where MVCC handles it for you.
Principle. Locks are a tax on concurrency. The bigger the lock, the higher the tax. Correct-but-slow under load eventually becomes just wrong, as timeouts cascade into retries into outages.
Mistake 2: Forgetting state lives outside your process too
A service has perfect in-memory locking. It scales to two replicas. The locks now do nothing — they only protect within one process. For state shared across machines, you need a coordination layer: a database transaction, a Redis lock, an idempotency key, or a queue with single-consumer semantics.
Principle. In-process locks don’t survive horizontal scaling. The day you add a second replica is the day your single-process locking assumptions quietly break.
Decision tree
Before reaching for a lock, walk this:
Is the shared state actually shared? Can each request own its own copy? If yes — do that, you’re done.
Is the operation a single read-modify-write on one value? Use an atomic. Done.
Are conflicts rare? Optimistic concurrency (version check, compare-and-swap) — fast in the happy path.
Are conflicts common, but the critical section small? A scoped mutex on the smallest unit you can.
Does the state live across machines? You’re not in lock territory anymore — you’re in distributed coordination territory. Reach for a database transaction, a queue, or an idempotency key.
Conclusion
And that’s all what I have for you guys today. Once you’ve got concurrency working and shared state under control, the next thing to break you is load itself. What happens when traffic exceeds capacity? Do requests queue forever? Do you drop them? Do you make the upstream slow down?
Next post: Why Your System Crashes Under Load — and How Kafka and SQS Push Back